PostgreSQL+Pgpool-IIのパフォーマンス検証
概要
PostgreSQLで負荷分散や高可用性(以下HA)を考慮する時、Pgpool-IIが候補に挙がることが多いかと思います。
では構成や設定によってどのくらいパフォーマンスに差が出るのか?
実際に検証してみました。
前提条件
PostgreSQLが構築されていること
環境
| OS | RHEL7.5 |
| RDBMS | postgresql-12.1-2 |
| 冗長化 | pgpool-II-pg12-3.7.12-1、pgpool-II-pg12-4.1.4-1 |
確認項目
- 負荷分散方式
Pgpool-IIはバージョン4.1から参照クエリの負荷分散方式の選択肢が増えています。
従来では負荷分散タイミングは「セッションごと」のみでしたが、「参照クエリごと」も選べるようになりました。
その負荷分散の方式で差が出るのか確認します。
そのため、環境でも記載しましたが、Pgpool-IIのバージョンを3.7.12(セッションごと)と4.1.4(参照クエリごと)で比較してみようと思います。
- サーバ構成
サーバ構成によって差が出るのか確認します。
今回はWEB/APサーバを動作させ、データをPostgreSQLで管理する想定です。
HAも考慮しているため、障害発生時のパターンも用意しています。
詳細は後述します。
- 参照クエリ接続の流れ
参照クエリを発行する接続元によって差が出るのか確認します。
※例えばAPサーバからVIPへの接続と、DBサーバからVIPへの接続のパフォーマンスは違うのか?など
こちらは複数台を使ったサーバ構成でないと検証出来ないので、2台以上の場合のみ確認します。
サーバ構成
では、実際に検証するサーバ構成パターンのご紹介です。
今回はWEB/APサーバを動作させ、データをPostgreSQLで管理する想定です。
HAも考慮しているため、障害発生時のパターンも用意しています。
- パターン1「WEB/AP+DB同一」
WEB/APプロダクトとPostgreSQLを同一サーバに載せた場合

- パターン2「WEB/AP1台+DB2台」
WEB/APプロダクトとPostgreSQLを同一サーバに載せた場合
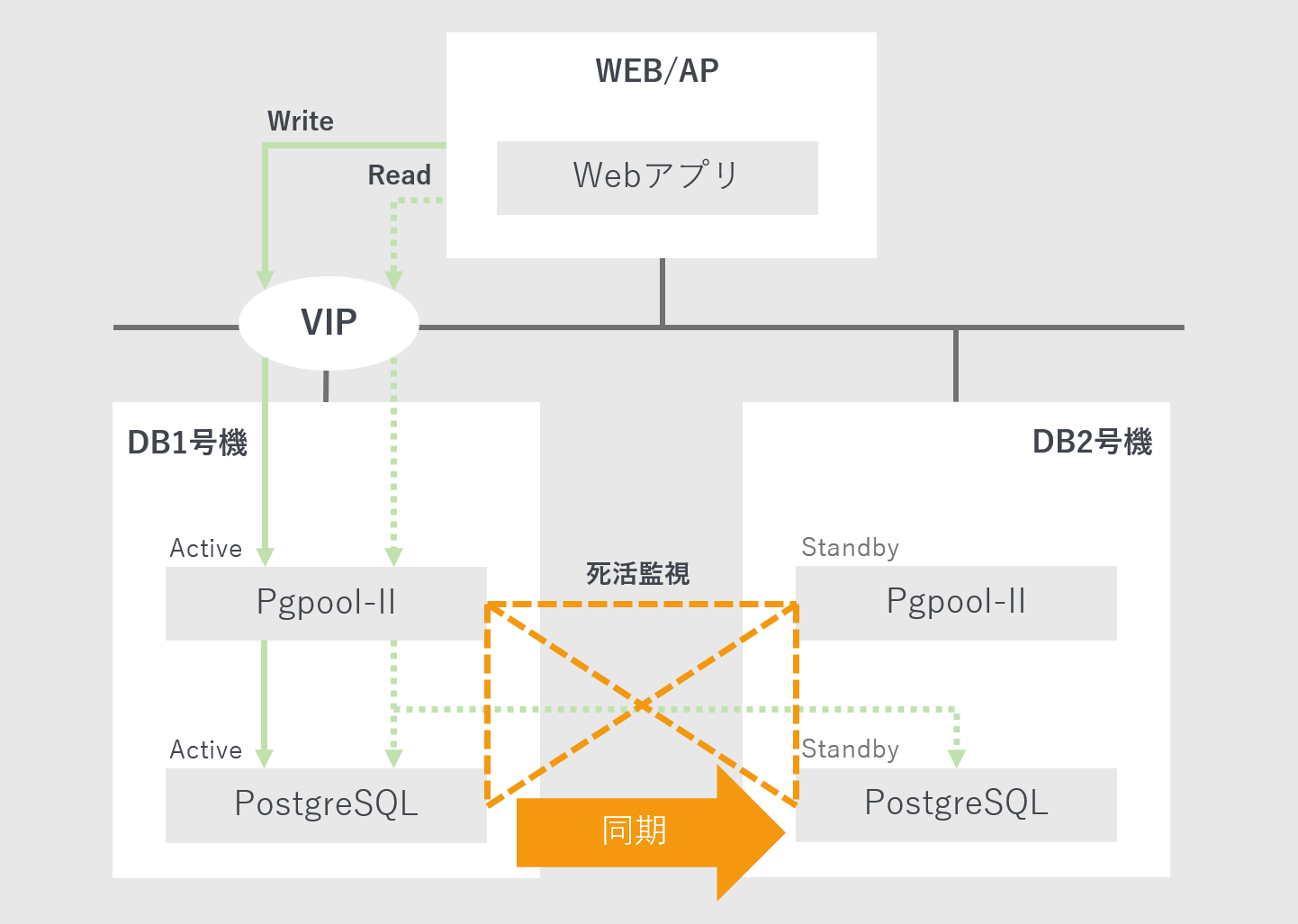
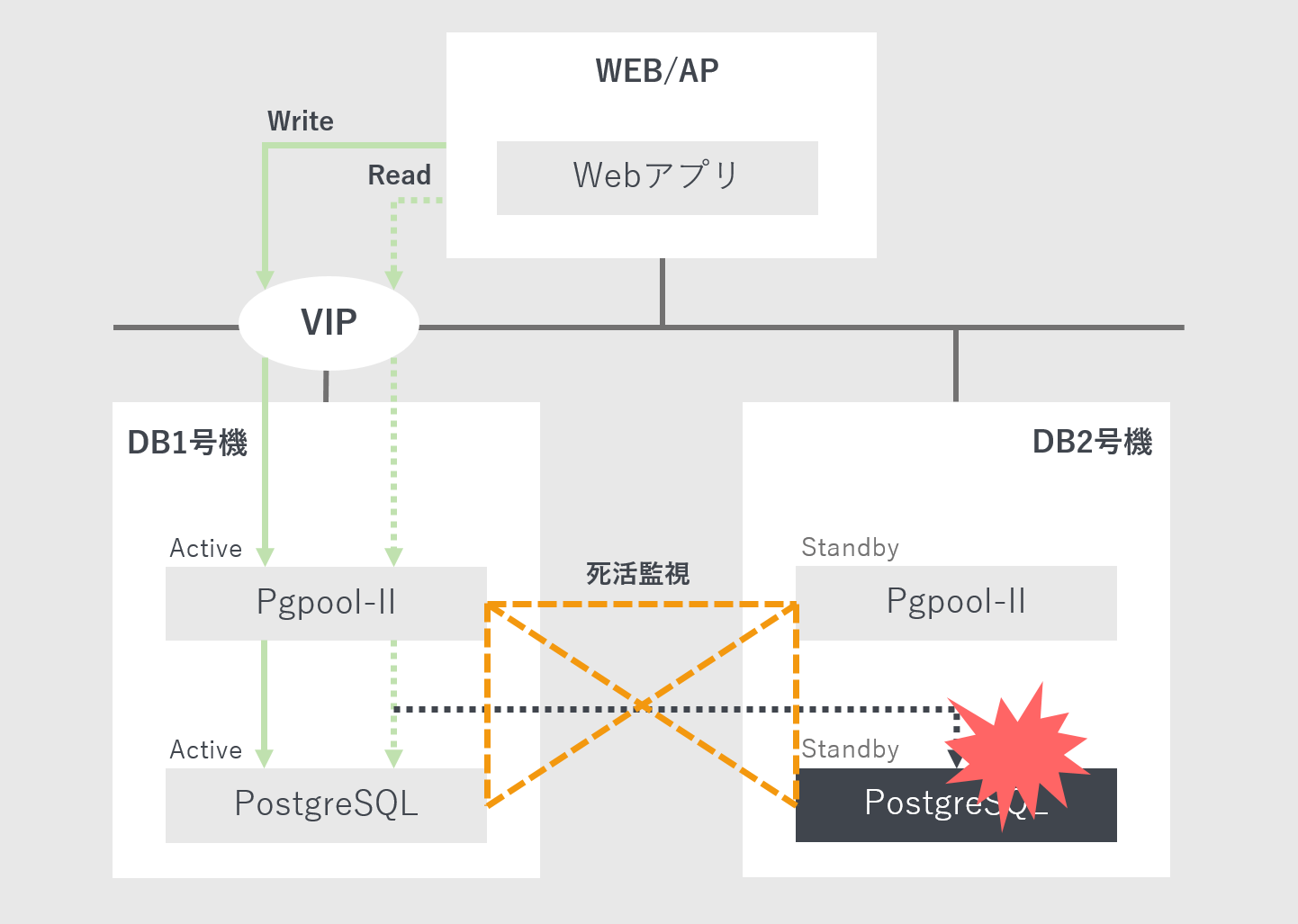
- パターン3「パターン2でDB1台に障害発生」
パターン2で用意したDBサーバ2台の内、1台に障害が発生した場合
(つまりWEB/APサーバ1台とDBサーバ1台です)
検証結果
この構成をもとにpsqlのselectコマンドを実施し、データ取得までの経過時間をtimeコマンドで取得しています。
結果がこちらです。
※検証のため複数回実施して確認しています。
| NO | 負荷分散方式 | サーバ構成 | 接続の流れ | 参照クエリ実施 | |
| 1000回 | 10000回 | ||||
| 1 | パターン1 (セッション開始ごと) | パターン1 (WEB/AP+DB同一) | AP | 0m31.994s 0m40.038s 0m36.583s | 5m34.679s 5m30.087s 5m38.237s |
| 2 | パターン2 (WEB/AP1台+DB2台) | AP→VIP | 0m39.999s 0m40.247s 0m41.039s | 6m38.958s 6m44.223s 6m18.860s | |
| 3 | パターン3 (パターン2でDB1台に障害発生) | AP→VIP | 0m31.280s 0m36.542s 0m39.651s | 6m19.631s 6m17.944s 6m23.442s | |
| 4 | パターン2 (参照クエリごと) | パターン2 (WEB/AP1台+DB2台) | AP→VIP | 0m34.199s 0m29.443s 0m26.704s | 4m57.208s 4m40.783s 4m45.716s |
| 5 | パターン3 (パターン2でDB1台に障害発生) | AP→VIP | 0m35.136s 0m35.244s 0m33.902s | 5m17.798s 5m38.673s 5m27.461s | |
この結果から下記のことが分かりました。
- 負荷分散方式
パターン1(セッション開始ごと)とパターン2(参照クエリごと)を比較するとパターン2の方が早い。 - サーバ構成
- 負荷分散方式パターン1(セッション開始ごと)の場合
サーバ構成パターン2(WEB/AP1台+DB2台)よりパターン3(パターン2でDB1台に障害発生)の方が早い。
パターン1(WEB/AP+DB同一)とパターン3は同じくらいの速度。 - 負荷分散方式パターン2(参照クエリごと)の場合
どのサーバ構成でもほぼ変わらない。
- 負荷分散方式パターン1(セッション開始ごと)の場合
- 参照クエリ接続の流れ
- 冗長化しない方が早い。
- 冗長化しない方が早い。
まとめ
ざっくりですが、まとめるとこんな感じになります。
- HAを考慮しないのであれば冗長化しない方が早い
- SELECT時の負荷分散をするのであれば参照クエリごと方式が早い
技術情報
関連サービス
お気軽にお問い合わせください。応対時間 9:30-17:30 [ 土・日・祝日除く ]
お問い合わせ